

Scraping sous Python
Scraper automatiquement un site internet sous Python avec la librairie BeautifulSoup
Le scraping consiste à récupérer des données de sites internet via une lecture automatisée des pages rendues. La structuration
en balises du code html rend cette opération relativement simple, d'autant qu'il existe de nombreuses librairies visant à nous
rendre la tâche plus facile. Nous allons étudier, dans cet article, l'une d'entre elles, à savoir BeautifulSoup.
Scraper un site peut répondre à divers besoins. Un commerçant peut, par exemple, vouloir extraire les prix d'articles similaires
aux siens chez des concurrents. Un data scientist peut encore se constituer un dataset via des données du web, etc ...
Notre objectif : scraper une liste de postes à pourvoir
Afin d'illustrer notre démarche, nous allons prendre un exemple concret. Nous désirons scraper une liste de postes à pourvoir
dans le domaine de la data ou de la gestion de projet, sur la ville de Rennes.
Notre objectif est de récupérer automatiquement la liste des postes afin de les compiler dans un dataframe.
Récupérer l'url de la cible
Nous allons tout d'abord nous rendre sur le site de pôle emploi, par exemple, afin d'initier les recherches et de récupérer
au final l'url générée.
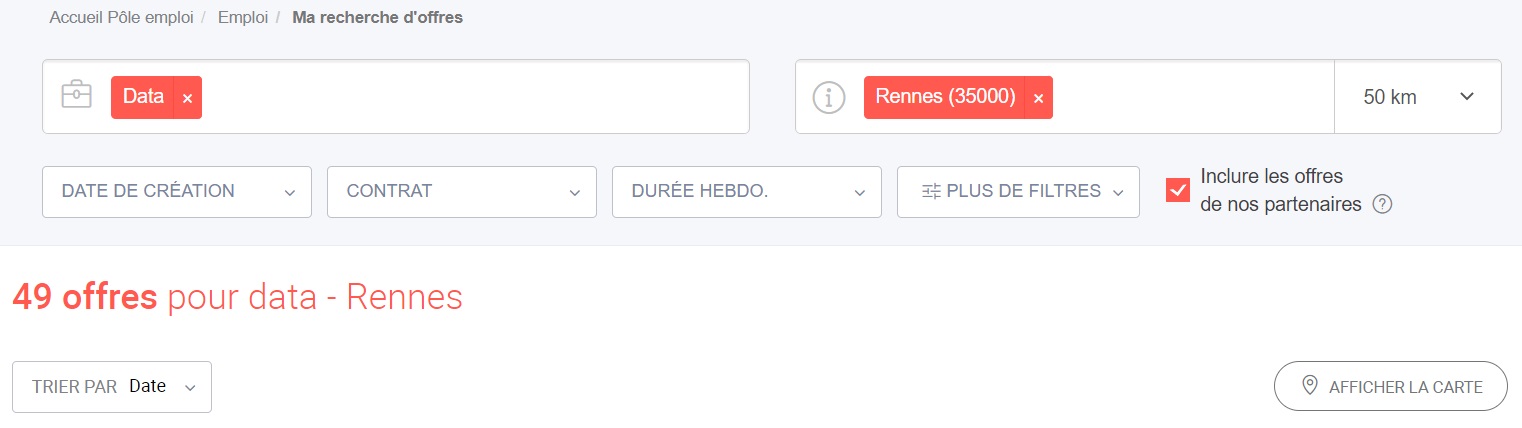
Comme vous le voyez, nous avons indiqué le seul domaine "data" pour l'instant, la ville de Rennes, le rayon de recherche (50Km), la prise en compte des offres partenaires ainsi que le tri des annonces par date. La recherche nous édite une page listant les offres, mais surtout l'url associée qui ressemble à ceci :
https://candidat.pole-emploi.fr/offres/recherche?lieux=35238&motsCles=data&offresPartenaires=true&range=0-19&rayon=50&tri=1
Trouver nos informations
Il faut que l'on sache quelles informations nous voulons récupérer et surtout ou elles se trouvent dans la page. Plus précisément
nous devons identifier un moyen unique et non ambigu de les cibler.
Pour l'exemple nous allons récupérer le titre du poste à pourvoir, sa description ainsi que le type de contrat proposé.
Pour identifier la position de ces informations dans la page, nous éditons via notre navigateur internet le code source
puis tentons de trouver les balises qui nous intéressent, comme illustré ci-dessous :

Nous constatons que les annonces sont listées dans un div issu de la classe results. Le titre de l'annonce est identifié par une balise de titre h2 de la classe media-heading et enfin la description et le type de contrat sont des paragraphes associés aux classes description et contrat. Nous avons ce qu'il nous faut, passons au codage de notre scraper sous Python.
Import des librairies
Nous n'aurons besoin, pour l'exemple, que de trois librairies, à savoir le requêtage html pour récupérer le contenu de la page, BeautifulSoup pour analyser la page récupérée et enfin pandas pour gérer notre dataframe.
from bs4 import BeautifulSoup
import requests
import pandas as pd
Implémentation du scraper
Nous voulons cibler deux domaines, data et gestion de projet. Nous allons déclarer une liste et les y entrer :
domaines = ["data", "chef de projet"]
Comme vous l'aurez compris, nous allons parcourir nos domaines afin de requêter pour chacun d'entre eux la liste des postes à pourvoir. Nous allons donc déclarer une fonction charger de récupérer la page résultante et passer le contenu à la moulinette de BeautifulSoup. Cette librairie va se charger pour nous de découper le contenu en fonction des balises.
def getData(domaine):
r = requests.get(
"https://candidat.pole-emploi.fr/offres/recherche?lieux=35238&motsCles="+domaine+"&offresPartenaires=true&range=0-19&rayon=50&tri=1")
data = r.text
soup = BeautifulSoup(data)
return soup
Nous retrouvons ci-dessus notre url. Nous avons néanmoins pris soin de stipuler le domaine en paramètre.
Nous pouvons désormais parcourir nos domaines puis requêter le site de pôle emploi. Pour chaque résultat obtenu,
nous allons parcourir les balises afin de cibler les informations qui nous intéressent et les stocker.
resultat = []
for domaine in domaines:
soup = getData(domaine)
if soup:
for link in soup.find_all('li', {'class':'result'}) :
titre = link.find('h2', {'class':'media-heading'}).text
contrat = link.find('p', {'class':'contrat'}).text
description = link.find('p', {'class':'description'}).text
origine = link.find('img').get('alt')
annonce = [titre,contrat,description,origine]
resultat.append(annonce)
resultat = pd.DataFrame(resultat, columns=('titre', 'contrat', 'description','origine'))
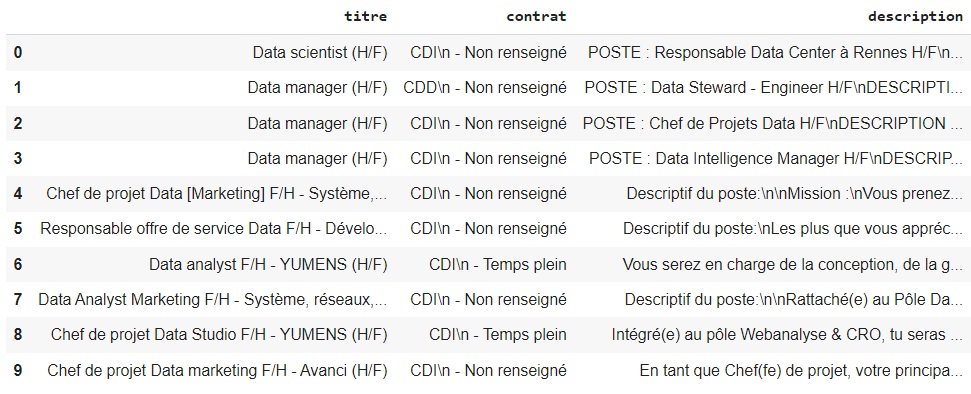
Nous y sommes, voici le résultat :
resultat.head(10)
Conclusion
Nous pouvons bien sur faire beaucoup mieux en termes de recherche, de précisions et de rendu. Les bases sont cependant bien la et montrent tout le potentiel du scraping avec BeautifulSoup.
Retrouvez dans la rubrique "Nos datasets" toutes les données dont vous aurez besoin pour tester et pratiquer !