

Ajout d'informations géographiques sous Python
Coordonnées géographiques, continents, données démographiques ou financières ... Un code pays suffit pour agrémenter vos données d'informations clés
Il existe en effet nombre d'API depuis lesquelles il est possible de récupérer un grand nombre d'informations. Dans le cadre de cet article nous allons, depuis un code pays, ajouter les coordonnées géographiques moyennes (latitude et longitude), la région du globe, sa dénomination, la population ainsi que le produit intérieur brut par habitant.
Données de travail
Nous allons travailler sur la base d'un dataset disponible sur Kaggle et présentant les émissions de CO2 (en kt) par pays et par année. Le dataset est disponible ici.
Chargeons le dataset et visualisons un extrait des données :
import numpy as np
import pandas as pd
data = pd.read_csv('../input/co2-emissions-by-country/co2_emissions_kt_by_country.csv')
data.head()
country_code country_name year value 0 ABW Aruba 1960 11092.675 1 ABW Aruba 1961 11576.719 2 ABW Aruba 1962 12713.489 3 ABW Aruba 1963 12178.107 4 ABW Aruba 1964 11840.743
Comme on peut le voir, le dataset ne compte que 4 colonnes, le code pays, sur 3 caractères, le nom
du pays, l'année et quantité de CO2 émise (en kt).
Ci-dessous la caractérisation du dataframe par Pandas :
data.info()
RangeIndex: 13953 entries, 0 to 13952 Data columns (total 4 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 country_code 13953 non-null object 1 country_name 13953 non-null object 2 year 13953 non-null int64 3 value 13953 non-null float64 dtypes: float64(1), int64(1), object(2) memory usage: 436.2+ KB
Le dataset ne comporte aucune valeur nulle. Par ailleurs, il compte 13953 observations.
Vérification du code pays via la norme ISO 3166
Les codes pays sont référencés sous la norme ISO 3166, aussi il est relativement simple de valider les codes d'un dataset en utilisant la librairie iso3166 standard. L'idée est de s'assurer que le code dont nous disposons est officiel et, par conséquent, sera accepté par les librairies tiers auxquelles nous allons faire appel par la suite.
Commençons par importer la librairie :
from iso3166 import countries
Implémentons ensuite une simple fonction qui va prendre en entrée notre code alphanumérique sur 3 caractères et retourner le code officiel sur 2 caractères. Nous appliquerons ensuite cette fonction sur les observations de notre dataset :
def isISO(alpha3):
try:
alpha2 = countries.get(alpha3).alpha2
except KeyError:
alpha2 = 'unknown'
return (alpha2)
data['country_code2'] = data.apply(lambda row : isISO(row['country_code']),
axis = 1)
Vous noterez dans le code ci-dessus que les pays non reconnus vont être associés à un code country_code2 inconnu. Nous n'allons conserver que les pays officiellement reconnus :
data = data[data['country_code2']!='unknown']
Informations géographiques
Les pays ayant été vérifiés, nous allons commencer par ajouter la région du globe dans laquelle se situe le pays, sa latitude et sa longitude moyenne. Ces informations sont disponibles via une API mise à disposition par World Bank Open Data :
Procédons à l'installation puis l'import de la librairie :
!pip install wbgapi --quiet
import wbgapi as wbo
Afin d'éviter le requêtage à outrance du serveur distant et accessoirement, un temps d'exécution à rallonge, il est préférable de charger dans un premier temps les données géographiques puis procéder à une jointure afin d'ajouter les informations attendues.
dataGeo1 = wbo.economy.DataFrame() #Get region code, latitude and longitude informations
data = pd.merge(data, dataGeo1[['region','latitude', 'longitude']],
how="left",
left_on=["country_code"],
right_on=["id"])
data.head()
Voici le résultat :
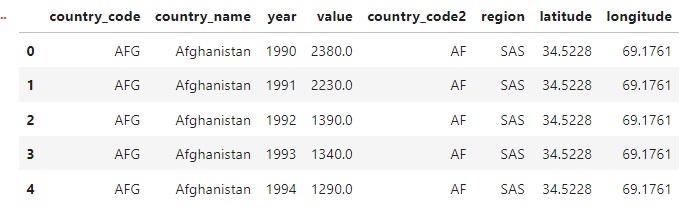
Le code région est un code alphanumérique sur 2 a N caractères. Les codes région disponibles sont les suivants :
EAP: East Asia and Pacific ECA: Europe and Central Asia LAC: Latin America and Caribbean MENA: Middle East and North Africa SA: South Asia SSA: Sub-Saharan Africa WORLD: World WB_EAP: East Asia & Pacific WB_ECA: Europe & Central Asia WB_LAC: Latin America & Caribbean WB_MNA: Middle East & North Africa WB_NAR: North America WB_SAR: South Asia WB_SSA: Sub-Saharan Africa GLOBAL: Global
Afin que leur interprétation soit plus simple, ajoutons la dénomination associée. Pour cela, nous allons procéder de la même façon que précédemment :
dataGeo2 = wbo.region.Series().to_frame() #Get region name
data = pd.merge(data, dataGeo2['RegionName'],
how="left",
left_on=["region"],
right_on=dataGeo2.index)
data.head()
Nous avons désormais le nom de la région :
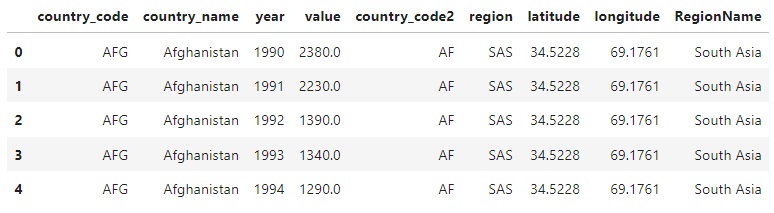
Coordonnées UTM
Les coordonnées UTM (pour Universal Transverse Mercator) sont une projection des coordonnées géographiques (latitude et longitude) sur un plan bi-dimensionnel cartésien permettant, vous l'aurez compris, de positionner un point sur un plan. Nous allons utiliser pour cela la librairie bien nommée : utm
!pip install utm --quiet
import utm
data['coord'] = data.apply(lambda x: utm.from_latlon(x.latitude, x.longitude)[0:2], axis=1)
data.head()
Notre dataframe ressemble desormais a ceci :

Données démographiques
World Bank Open Data regorge d'informations, aussi, nous vous conseillons d'effectuer quelques recherches à ce sujet. Pour illustrer notre propos, nous allons nous contenter d'ajouter la population par pays et par année :
#Pick up population on working timeframe for all countries
df_pop = wbo.data.DataFrame('SP.POP.TOTL', data['country_code'].unique(), range(1990, 2019, 1))
df_pop.columns = df_pop.columns.str.lstrip("YR")
df_pop = df_pop.reset_index()
df_pop = df_pop.melt(id_vars='economy')
df_pop = df_pop.rename({'economy': 'country_code', 'variable': 'year', 'value': 'population'}, axis=1)
df_pop['year'] = df_pop['year'].astype(int)
data = pd.merge(data, df_pop, on=['country_code', 'year'], how='left')
data.head()
Comme vous le constatez, nous procédons toujours selon la même logique. Tout d'abord un import de l'indicateur (ici SP.POP.TOTL) sur lequel nous imposons un ou plusieurs filtres, puis une jointure sur notre dataframe. Les filtres que nous avons mis en place lors de l'import portent sur les codes pays (data['country_code'].unique) ainsi que les années (ici 1990 à 2019) :

Produit intérieur brut par habitant
Enfin, la dernière information que nous allons ajouter : le produit intérieur brut par habitant :
#Pick up gross domestic product per capita and per year on working timeframe for all countries
df_gdp = wbo.data.DataFrame('NY.GDP.PCAP.CD', data['country_code'].unique(), range(1990, 2019, 1))
df_gdp.columns = df_gdp.columns.str.lstrip("YR")
df_gdp = df_gdp.reset_index()
df_gdp = df_gdp.melt(id_vars='economy')
df_gdp = df_gdp.rename({'economy': 'country_code', 'variable': 'year', 'value': 'gdp_pcap'}, axis=1)
df_gdp['year'] = df_pop['year'].astype(int)
data = pd.merge(data, df_gdp, on=['country_code', 'year'], how='left')
data[data['country_code']=='JPN'].head()
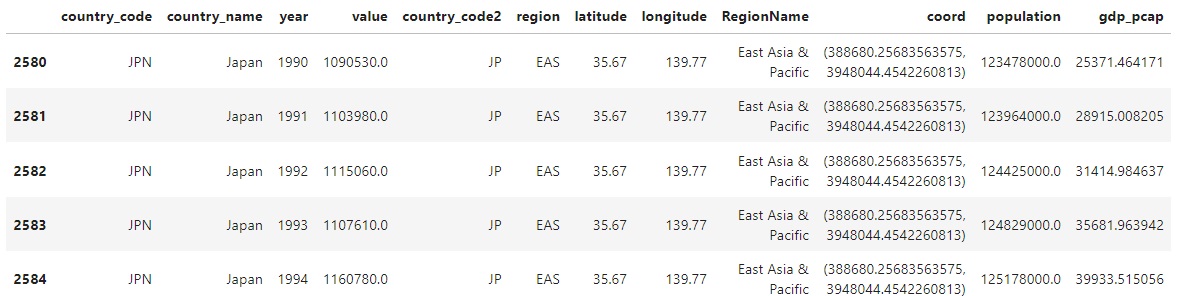
Crédits
Image de la miniature : de GarryKillian sur Freepik
Retrouvez dans la rubrique "Nos datasets" toutes les données dont vous aurez besoin pour tester et pratiquer !