

Gérez les valeurs manquantes avec Pandas
Détectez puis supprimez ou remplacez les valeurs manquantes de vos datasets sous Python avec Pandas
Les données sont bien souvent inexploitables en l'état et nécessitent, avant toute analyse, un nettoyage. Il
s'agit, dit-on, des deux tiers du travail d'un data analyste. Aussi, tous les outils qui vont nous faciliter
la vie dans ce domaine sont les bienvenus. Pandas, librairie bien connue des datascientists, en fait partie.
Le nettoyage des données peut prendre plusieurs formes. Il s'agit principalement d'une part, de gérer les doublons ou
d'effectuer des opérations de retraitement voir de remplacement des données, et d'autre part, de gérer les valeurs
manquantes. Nous allons, dans cet article, nous concentrer sur ce second point.
Données de travail
Nous allons travailler avec la base clients d'une société de vente en ligne. Ce dataset est disponible sur Gorenja.com ici. Chargeons tout d'abord la librairie Pandas puis notre fichier afin d'en lister un extrait.
import pandas as pd
df = pd.read_csv('clients.csv' , sep = ';')
df.head(3)
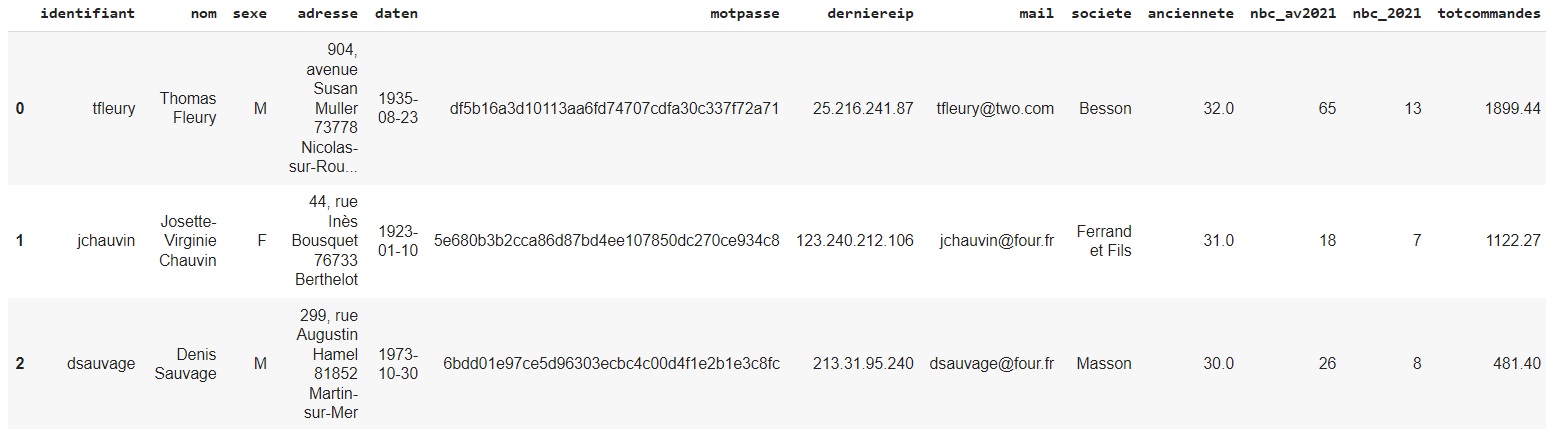
Comme vous le voyez, nous disposons d'un certain nombre d'informations : l'identifiant du client, son nom complet, son sexe, son adresse complète, sa date de naissance au format AAAA-MM-JJ, son mot de passe crypté, sa dernière adresse IP connue, son adresse mail, sa société, son ancienneté (nombre de mois écoulés depuis son inscription), le nombre de commandes passées avant 2021 et en 2021 et enfin le total commandé en euros.
Détection des valeurs manquantes
Sous Pandas, la détection des valeurs manquantes peut se faire assez simplement dans la mesure où la classe Dataframe dispose d'un certain nombre de méthodes prévues à cet effet.
isna()
Il s'agit de la méthode principale et indispensable. Elle va venir scanner les cellules d'un dataframe pour déceler
si la valeur est de type np.nan ou None. La méthode renvoie un dataframe de même dimension que l'original et constitué
de booleen (True si la valeur de la cellule est manquante, False dans le cas contraire). Le fait qu'un dataframe soit renvoyé
va nous permettre d'exploiter un certain nombre de méthodes complémentaires par la suite.
Il faut préciser que les méthodes isna() et isnull() sont strictement identiques, puisqu'il s'agit d'alias. Par ailleurs,
la méthode isna() peut être considérée comme étant de niveau supérieur à isnan() de Numpy, dans la mesure où isnan() va tester
les valeurs numériques np.nan() uniquement.
Ci-dessous un exemple :
df.isna()
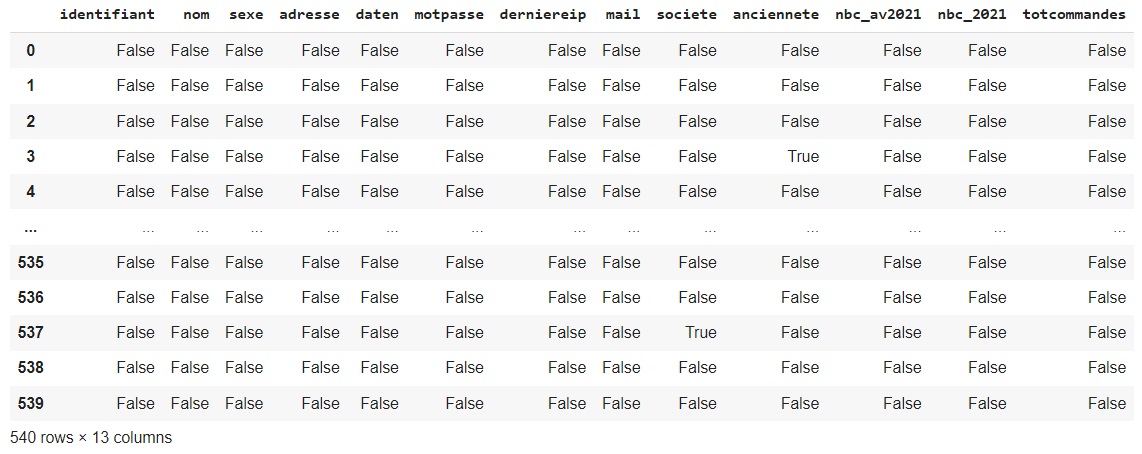
Sur notre dataset, nous pouvons voir, par exemple, que le 4eme client (index numéro 3) comporte une valeur manquante sur son ancienneté. Allons plus loin et tachons de résumer la présence de valeurs manquantes par colonne.
isna() + any()
La méthode any() couplée à isna() va nous permettre de résumer l'information, inexploitable en l'état, du moins sur des
grands set de données. Il faut comprendre any() comme "y a-t-il au moins une valeur True ?". A cette question, à l'instar de
isna(), nous allons recevoir un booléen. La méthode any() est intéressante dans la mesure où elle permet de résumer
l'information selon les axes : paramètre axis=0 pour les colonnes, axis=1 pour les observations :
df.isna().any(axis = 0)
identifiant True nom True sexe True adresse True daten True motpasse False derniereip False mail True societe True anciennete True nbc_av2021 False nbc_2021 False totcommandes False dtype: bool
La synthèse par colonne ci-dessus nous permet de constater que nous avons au moins une valeur manquante pour les colonnes identifiant, nom, sexe, adresse, daten, mail, societe et anciennete.
df.isna().any(axis = 1)
0 False
1 False
2 False
3 True
4 False
...
535 False
536 False
537 True
538 False
539 False
Length: 540, dtype: bool
La synthèse par observation ci-dessus est moins pertinente en l'état.
isna() + sum()
La méthode sum() couplée à isna() va nous permettre de connaitre le nombre total de valeurs manquantes. A l'instar de
any(), il convient de préciser un axe de synthèse pour gagner en précision :
df.isna().sum(axis = 0)
identifiant 2 nom 2 sexe 8 adresse 3 daten 4 motpasse 0 derniereip 0 mail 4 societe 26 anciennete 5 nbc_av2021 0 nbc_2021 0 totcommandes 0 dtype: int64
La combinaison isnan + sum par colonne nous permet de qualifier un dataset très rapidement. Elle constitue une première base de travail.
Affichage des observations concernées
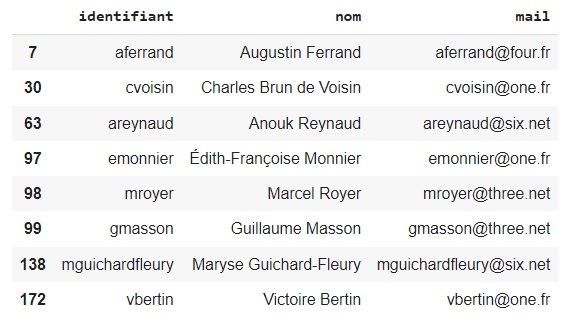
Puisque isna() nous retourne un booléen, il est relativement simple, via l'indexation conditionnelle, d'afficher les individus concernés. Affichons par exemple l'identifiant, le nom ainsi que l'adresse mail des clients dont le sexe est manquant :
df[df['sexe'].isna()][['identifiant', 'nom', 'mail']]
Retraitement des valeurs manquantes
Par retraitement, il faut comprendre remplacement. Chaque cas est spécifique, il y a bien sur autant de possibilités et règles de gestion que de cas d'étude. Dans cet article, nous nous intéressons aux remplacements systématiques. En l'occurrence nous allons travailler avec la méthode fillna() en prenant soin de préciser la colonne sur laquelle on agit. Pandas peut travailler sur le dataframe entier mais ce n'est pas recommandé si l'on veut rester maitre des actions que l'on applique sur le jeu de données.
Variables numériques
Concernant le remplacement systématique de valeurs manquantes sur des colonnes numériques, il est courant de combler
les trous avec une constante, la moyenne arithmétique de la colonne, la médiane ou encore la valeur minimum ou maximum.
Voici quelques exemples :
#Donnees orignales
df['anciennete']
# 1 . Remplacement des valeurs manquantes d'anciennete par une constante (ici 0)
df_tmp = df.copy()
df_tmp['anciennete'] = df_tmp['anciennete'].fillna(0)
df_tmp['anciennete']
# 2 . Remplacement des valeurs manquantes d'anciennete par la moyenne des clients
df_tmp = df.copy()
moyenne_anciennete = df_tmp['anciennete'].mean()
df_tmp['anciennete'] = df_tmp['anciennete'].fillna(moyenne_anciennete)
df_tmp['anciennete']
# 3 . Remplacement des valeurs manquantes d'anciennete par la mediane
df_tmp = df.copy()
mediane_anciennete = df_tmp['anciennete'].median()
df_tmp['anciennete'] = df_tmp['anciennete'].fillna(mediane_anciennete)
df_tmp['anciennete']
# 4 . Remplacement des valeurs manquantes d'anciennete par la valeur maximum
df_tmp = df.copy()
max_anciennete = df_tmp['anciennete'].max()
df_tmp['anciennete'] = df_tmp['anciennete'].fillna(max_anciennete)
df_tmp['anciennete']

Variables catégorielles
Pour les variables catégorielles, il est courant de remplacer les valeurs manquantes par une catégorie arbitraire qui peut
faire partie des modalités (ex H ou F pour le sexe), ou non (‘inconnu’ par exemple) si l'on veut conserver l'information selon laquelle
cette donnée était manquante. Vous noterez dans ce second cas de figure que l'on crée ainsi une modalité supplémentaire.
Une autre possibilité est de remplacer les valeurs manquantes par le mode, c'est à dire la
valeur la plus représentée dans la colonne.
Voici quelques exemples pour la colonne sexe :
#Donnees orignales (lignes 4 a 12 uniquement)
df.loc[4:12]['sexe']
# 1 . Remplacement des valeurs manquantes par le mode
df_tmp = df.copy()
sexeMode = df_tmp['sexe'].mode()
df_tmp['sexe'] = df_tmp['sexe'].fillna(sexeMode[0])
df_tmp.loc[4:12]['sexe']
# 2 . Remplacement des valeurs manquantes par une constante
df_tmp = df.copy()
df_tmp['sexe'] = df_tmp['sexe'].fillna('inconnu')
df_tmp.loc[4:12]['sexe']

Suppression des valeurs manquantes
En matière de suppression, la principale méthode à connaitre est dropna(). Cette méthode dispose de 3 arguments qui,
combinés entre eux, nous permettent de faire à peu près tout.
- axis nous offre la possibilité supprimer les lignes (axis=0) ou les colonnes (axis=1),
- how nous permet d'indiquer la règle de gestion à suivre, how='any' si la ligne (ou la colonne) doit être supprimée
si elle contient au moins une valeur manquante, how='all' pour une ligne (ou une colonne) ne contenant que des valeurs
manquantes,
- subset pour spécifier les colonnes de la recherche.
Voici quelques exemples :
# Suppression de toutes les lignes contenant au moins une valeur manquante
df = df.dropna(axis = 0, how = 'any')
# Suppression des colonnes vides
df = df.dropna(axis = 1, how = 'all')
# Suppression des lignes ayant des valeurs manquantes
# dans les colonnes 'mail' et 'societe'
df = df.dropna(axis = 0, how = 'all', subset = ['mail', 'societe'])
Crédits
Miniature issue de Freepik
Retrouvez dans la rubrique "Nos datasets" toutes les données dont vous aurez besoin pour tester et pratiquer !