

Superposition d'histogrammes sous R
Dressez un histogramme par modalité d'une variable catégorielle et superposez-les sur un même diagramme
La superposition de graphiques est un moyen très efficace pour faire passer un message. L'impact visuel
est instantané et amène un liant à l'interprétation de l'analyste. L'histogramme est particulièrement bien
adapté à la superposition, sous réserve que les distributions associées à chacune des modalités catégorielles
soient suffisamment bien réparties pour garantir la pertinence d'une telle opération.
Voici le résultat de ce que nous allons implémenter dans cet article :
Données de travail
Nous allons travailler avec un jeu de données reprenant les résultats d'expérimentation d'un laboratoire d'agronomie sur les rendements de diverses variétés de blé. Ce dataset est disponible ici.
Nous allons tout d'abord charger nos données dans un dataframe "df_ble", puis visualiser un extrait :
df_ble <- read.table("ble.csv", header = TRUE,
sep = ";",
quote = "\"",
fill = TRUE,
comment.char = "")
head(df_ble)
lot variete conditions epiaison rendement
1 S2001 MU430 medium precoce 938.45
2 S2002 MU430 medium precoce 949.49
3 S2003 MU430 medium precoce 942.43
4 S2004 MU430 medium precoce 936.01
5 S2005 MU430 medium precoce 944.55
6 S2006 MU430 medium precoce 932.99
...
Le jeu de données comporte 4 variétés de blé (MU430, RA226, PO400 ou KI133). Chacune des variétés a été soumise à des conditions diverses de température et d'ensoleillement (chaudes, medium et froides). Dans le cadre de cet article nous allons nous concentrer sur la seule variété MU430. Par ailleurs, les informations concernant le lot ainsi que la phase d'épiaison ne vont pas nous être utiles.
Notre base : l'histogramme
Dressons rapidement l'histogramme nous permettant de visualiser la distribution du rendement de la variété MU430 en conditions medium. Nous allons ajouter à cet histogramme la courbe de densité ainsi que la moyenne sous forme d'une ligne verticale :
Commençons par isoler la variété MU430 en medium dans un dataframe dédié :
df_bleMU430medium <- df_ble[(df_ble$conditions=='medium')&
(df_ble$variete=='MU430'),]
Chargeons ensuite la librairie ggplot2 :
library(ggplot2)
theme_set(
theme_classic() +
theme(legend.position = "top")
)
Dressons à présent l'histogramme :
ggplot(df_bleMU430medium, aes(x = rendement, y=..density..)) +
geom_histogram(color = 'white', fill="#E7B800",
bins = 9, alpha = 1) +
geom_density(data=df_bleMU430medium, aes(x = rendement, y=..density..), alpha = 0) +
ggtitle("Rendement MU430 / Conditions medium") +
geom_vline(aes(xintercept=mean(rendement)))+
xlab("Rendement (g/m2)") + ylab("Densité") +
theme(
plot.title = element_text(size=12, hjust = 0.5, face="bold", color="black"),
axis.title = element_text(size=12),
axis.text.x = element_text(size = 9)
)

Histogrammes mutliples
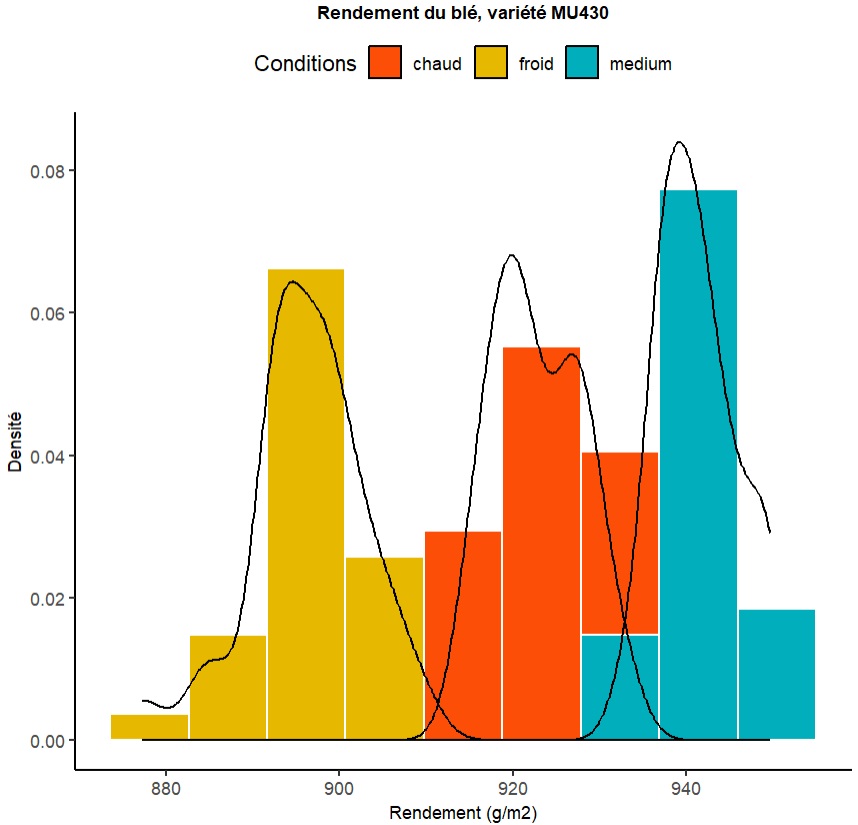
Il est courant de vouloir dresser, sur la base d'une variable catégorielle du jeu de données, autant d'histogrammes que de modalités. Dans certains cas, il est tout à fait possible de les superposer sur un même diagramme. Dans notre cas, nous voulons superposer les histogrammes des rendements de la variété MU430 associés aux conditions froides, medium et chaudes :
Isolons la variété MU430, toutes conditions confondues, dans un dataframe dédié :
df_bleMU430 <- df_ble[(df_ble$variete=='MU430'),]
Puis dressons le diagramme :
histColor <- c("#FC4E07", "#00AFBB", "#E7B800")
ggplot() +
geom_histogram(data=df_bleMU430, aes(x = rendement, y=..density.., fill = conditions), bins = 9, color='white') +
ggtitle("Rendement du blé, variété MU430") +
xlab("Rendement (g/m2)") + ylab("Densité") +
geom_density(data=df_bleMU430, aes(x = rendement, y=..density.., fill = conditions), alpha = 0) +
scale_fill_manual(name ="Conditions", values = histColor) +
theme(
plot.title = element_text(size=9, hjust = 0.5, face="bold", color="black"),
axis.title = element_text(size=9)
)
Les différences, par rapport à l'histogramme unique, résident principalement dans l'ajout d'une option « fill » par conditions, pour les histogrammes comme pour les courbes de densité, ainsi que l'utilisation de scale_fill_manual pour rediriger les couleurs vers notre palette (nommée histColor). Vous noterez enfin l'alpha à 0 pour les courbes de densité afin de ne conserver que les courbes retraçant la forme de la distribution et ôter le remplissage.
Retrouvez dans la rubrique "Nos datasets" toutes les données dont vous aurez besoin pour tester et pratiquer !