

Tri et dédoublonnage sous SAS
Triez vos tables et éliminez les doublons avec PROC SORT
Si utiliser la PROC SORT pour trier une table semble tout naturel, s'en servir pour supprimer les doublons l'est moins. C'est pourtant une option bien pratique que nous allons aborder dans cet article.
Données de travail
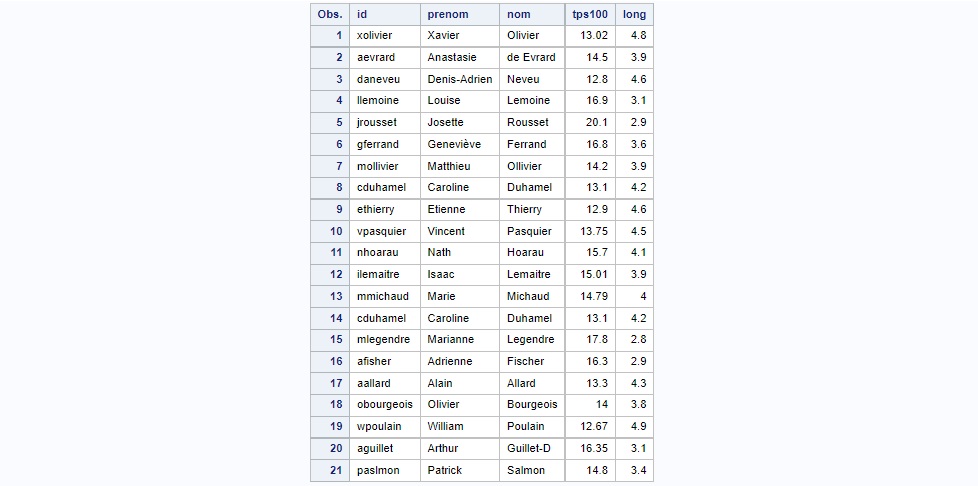
Nous allons travailler pour illustrer nos propos avec un dataset listant les performances sportives des élèves d'une classe de collèges. Le dataset liste 21 élèves, filles et garçons confondus, et porte sur deux épreuves : le 100 mètres et le saut en longueur. Chargeons les données et voyons à quoi elles ressemblent.
options validvarname=any;
filename FILE "/home/u49997643/gorenja/eps.txt"
encoding='utf-8' ;
proc import datafile=FILE out=work.eps dbms=dlm replace;
delimiter = ';';
getnames = yes;
run;
proc print data=work.eps;
run;
Tri
Commençons par ce pour quoi PROC SORT est avant tout destiné, à savoir le tri d'une table. L'implémentation est assez intuitive. Par défaut tout tri dont le sens n'est pas spécifié sera fait par ordre croissant. Ainsi si nous voulons trier nos élèves par performances aux 100 mètres du plus rapide au plus lent, nous allons procéder ainsi :
proc sort data=work.eps out=work.eps_trie;
by tps100;
run;
Comme vous le voyez il nous suffit de spécifier le champ sur lequel va porter le tri. Nous avons par ailleurs
redirigé la sortie vers une nouvelle table via l'option : out=work.eps_trie
Trions maintenant les élèves du plus rapide au plus lent sur 100 mètres et du plus performant ou moins performant au
saut en longueur (par ordre décroissant donc sur cette épreuve) :
proc sort data=work.eps out=work.eps_trie;
by tps100 descending long;
run;
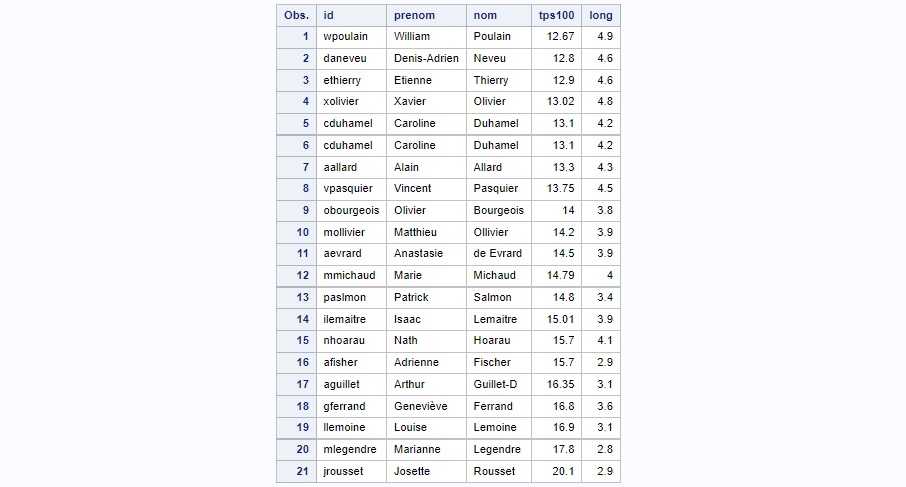
Le tri décroissant s'effectue en indiquant le mot clé descending devant la variable concernée. Ce mot clé n'est valable
que pour la variable qui suit. Nous remarquons que les individus 15 et 16, qui ont un temps aux 100 mètres identique, ont
bien été ordonnés selon leur performance au saut en longueur.
Précisons, par ailleurs, que le tri est bien entendu tout à fait possible sur les variables texte.
Nous pouvons remarquer, sur la sortie ci-dessus, qu'une élève figure en doublon dans le dataset (observations 5 et 6). Ceci
nous amène à notre second volet, la suppression des doublons.
Suppression des lignes adjacentes en doublon
Un doublon, au sens général du terme, est une ligne en double. C'est ce cas de figure que nous allons évoquer ici. Il faut néanmoins
savoir que SAS permet de définir un doublon sur la base d'une ou plusieurs variables à spécifier. Nous verrons ce cas un peu plus loin.
PROC SORT va procéder en deux temps pour supprimer les lignes en double. La table va tout d'abord être triée puis les lignes adjacentes
identiques vont être supprimées. Celles-ci peuvent être stockées dans une table dédiée.
proc sort data=work.eps out=work.eps_trie noduprecs dupout=doublons;
By _all_;
run;
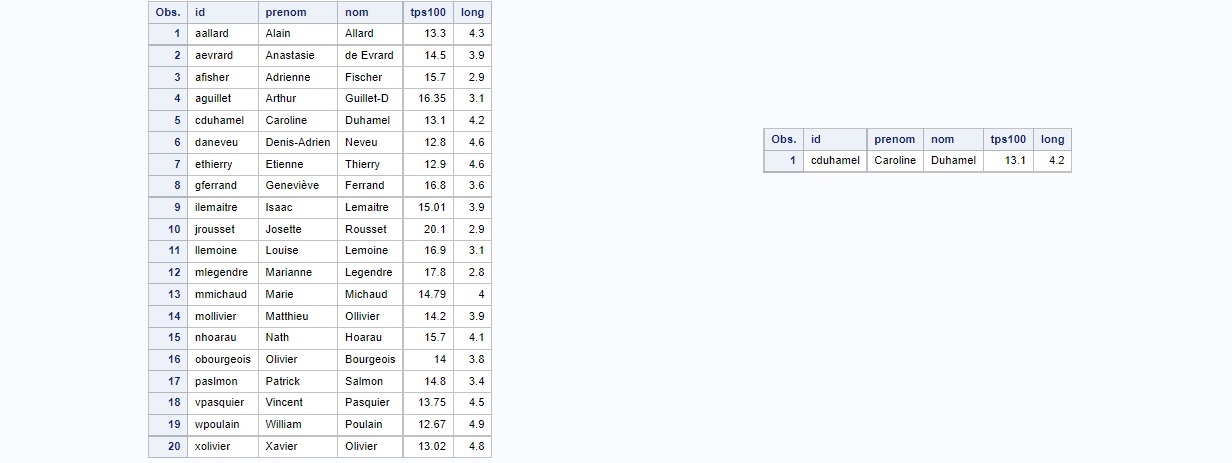
Ci-dessus à gauche, nous remarquons que la table de sortie ne comporte plus de lignes en double. Par ailleurs, la table se retrouve triée
par ordre croissant sur la première colonne, à savoir l'id. A droite, nous avons la table dans laquelle SAS a stocké les doublons, puisque nous
lui avons demandé, via l'option dupout de rediriger les lignes adjacentes en double dans la table doublons.
Il faut noter, par ailleurs, que SAS dans son journal stipule le nombre d'observations supprimées :
NOTE: There were 21 observations read from the data set WORK.EPS. NOTE: 1 duplicate observations were deleted. NOTE: The data set WORK.EPS_TRIE has 20 observations and 5 variables. NOTE: The data set WORK.DOUBLONS has 1 observations and 5 variables.
Suppression des doublons sur clés
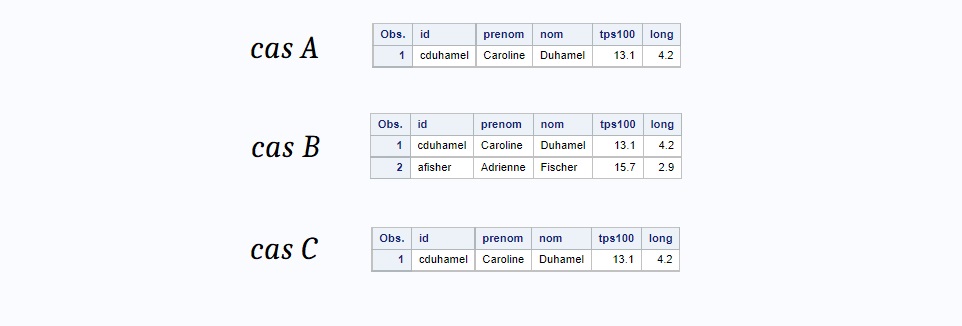
Nous allons ici définir sur la base de quelle(s) variables(s) nous estimons qu'une observation est en doublon. Nous pourrions, par exemple, supprimer toutes les observations en surnombre sur la base de l'id, ce qui reviendrait à la même opération que précédemment. Nous pourrions encore ne vouloir conserver qu'une seule observation par temps aux 100 mètres. Ou enfin combiner les deux.
/* A : suppression des doublons sur la cle : id */
proc sort data=work.eps out=work.eps_trie nodupkey dupout=doublons;
By id;
run;
/* B : suppression des doublons sur la cle : tps100 */
proc sort data=work.eps out=work.eps_trie nodupkey dupout=doublons;
By tps100;
run;
/* C : suppression des doublons sur la cle : id / tps100 */
proc sort data=work.eps out=work.eps_trie nodupkey dupout=doublons;
By id tps100;
run;
Retrouvez dans la rubrique "Nos datasets" toutes les données dont vous aurez besoin pour tester et pratiquer !