

Un visuel façon carte PowerBI sous Python
Donnez à vos graphiques plus d'impact en ajoutant des informations clés
S'il est un atout qu'il faut bien reconnaitre aux logiciels de data visualisation comme PowerBI ou encore Tableau, pour ne citer que ces deux-là, c'est la facilité avec laquelle il est possible de générer des visuels à forte valeur ajoutée. Il faut comprendre par là, des graphiques qui se suffisent à eux-mêmes et dont la compréhension, par le lecteur, est simple et efficace.
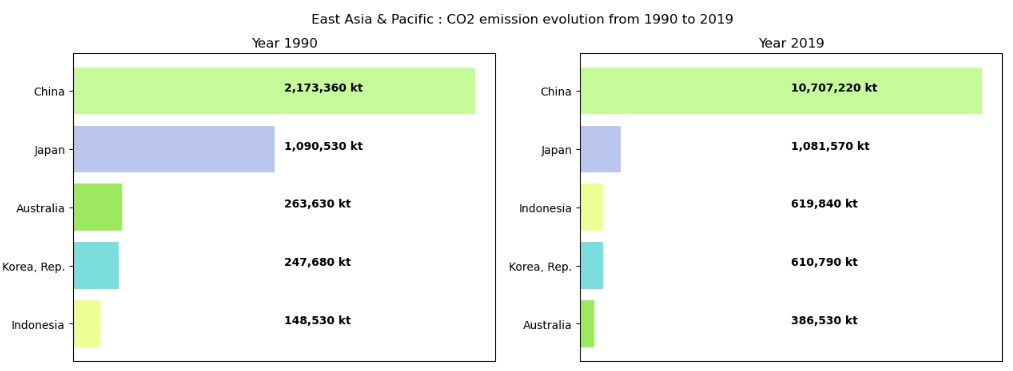
Nous allons, dans cet article, tenter de réaliser un visuel de type carte PowerBI sur la base d'un diagramme en barres Mathplotlib. En l'occurrence, il va s'agir de présenter le top 5 des pays émetteur de CO2 en Asie. Voici le résultat auquel nous allons arriver :
Données de travail
Nous allons travailler sur la base d'un dataset disponible sur Kaggle et présentant les émissions de CO2 (en kt) par pays et par année entre 1960 et 2019. Le dataset est disponible ici.
Chargeons le dataset et visualisons un extrait des données :
import numpy as np
import pandas as pd
data = pd.read_csv('../input/co2-emissions-by-country/co2_emissions_kt_by_country.csv')
data.head()
country_code country_name year value 0 ABW Aruba 1960 11092.675 1 ABW Aruba 1961 11576.719 2 ABW Aruba 1962 12713.489 3 ABW Aruba 1963 12178.107 4 ABW Aruba 1964 11840.743
Comme on peut le voir, le dataset ne compte que 4 colonnes, le code pays, sur 3 caractères, le nom
du pays, l'année et la quantité de CO2 émise (en kt).
Ci-dessous la caractérisation du dataframe par Pandas :
data.info()
RangeIndex: 13953 entries, 0 to 13952 Data columns (total 4 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 country_code 13953 non-null object 1 country_name 13953 non-null object 2 year 13953 non-null int64 3 value 13953 non-null float64 dtypes: float64(1), int64(1), object(2) memory usage: 436.2+ KB
Le dataset ne comporte aucune valeur nulle. Par ailleurs, il compte 13953 observations.
Prétraitement des données
La partie que va suivre ne fait pas l'objet de cet article, mais elle n'en demeure pas moins une étape essentielle puisqu'elle va consister à nettoyer et équilibrer les données. Nous travaillons sur un dataset tiers, aussi ce travail s'avère souvent nécessaire.
Les pays sont-ils tous reconnus ?
Pour nous en assurer nous allons soumettre le code pays sur 3 caractères, que nous avons, à la norme ISO 3166 afin de récupérer le code pays standard sur 2 caractères. Pour ce faire, nous installons la librairie ISO3166, importons celle-ci puis, via une fonction maison de conversion, allons transcoder les pays via la méthode apply :
Installation de la librairie ISO3166 :
pip install iso3166 --quiet
Import du package countries de la librairie ISO3166 :
from iso3166 import countries
Transcodification des pays :
def isISO(alpha3):
try:
alpha2 = countries.get(alpha3).alpha2
except KeyError:
alpha2 = 'unknown'
return (alpha2)
data['country_code2'] = data.apply(lambda row : isISO(row['country_code']),
axis = 1)
Vous pouvez noter que nous avons ainsi créé une nouvelle colonne country_code2 qui
va prendre la valeur unknown si le code pays n'est pas reconnu.
Il nous reste désormais à visualiser les pays rejetés :
print("Nombre de pays inconnus : {}" .
format(data[data['country_code2']=='unknown']['country_name'].nunique()))
print(data[data['country_code2']=='unknown']['country_name'].unique())
Nombre de pays inconnus : 48 ['Africa Eastern and Southern' 'Africa Western and Central' 'Arab World' 'Central Europe and the Baltics' 'Caribbean small states' 'East Asia & Pacific (excluding high income)' 'Early-demographic dividend' 'East Asia & Pacific' 'Europe & Central Asia (excluding high income)' 'Europe & Central Asia' 'Euro area' 'European Union' 'Fragile and conflict affected situations' 'High income' 'Heavily indebted poor countries (HIPC)' 'IBRD only' 'IDA & IBRD total' 'IDA total' 'IDA blend' 'IDA only' 'Latin America & Caribbean (excluding high income)' 'Latin America & Caribbean' 'Least developed countries: UN classification' 'Low income' 'Lower middle income' 'Low & middle income' 'Late-demographic dividend' 'Middle East & North Africa' 'Middle income' 'Middle East & North Africa (excluding high income)' 'North America' 'OECD members' 'Other small states' 'Pre-demographic dividend' 'Pacific island small states' 'Post-demographic dividend' 'South Asia' 'Sub-Saharan Africa (excluding high income)' 'Sub-Saharan Africa' 'Small states' 'East Asia & Pacific (IDA & IBRD countries)' 'Europe & Central Asia (IDA & IBRD countries)' 'Latin America & the Caribbean (IDA & IBRD countries)' 'Middle East & North Africa (IDA & IBRD countries)' 'South Asia (IDA & IBRD)' 'Sub-Saharan Africa (IDA & IBRD countries)' 'Upper middle income' 'World']
48 observations ont été rejetées, il ne s'agit pas de pays mais essentiellement d’indicateurs démographiques ou économiques. Ces indicateurs ne nous intéressent pas dans le cadre de cet article, nous allons par conséquent les filtrer :
data = data[data['country_code2']!='unknown']
Combien de pays avons-nous ?
Suite au nettoyage que nous avons effectué, combien de pays distincts avons-nous ?
checkCodeName = data.groupby(data['country_code'])['country_name'].nunique()
countUniqueCC = data['country_code'].nunique()
print("{} pays distincts".format(countUniqueCC))
207 pays distincts
Nous en avons profité pour stocker au passage dans une variable checkCodeName les codes pays distincts.
Les pays ont-ils tous le même timeframe ?
Nous avons dit en introduisant le dataset que celui-ci couvrait une période allant de 1960 à 2019. Nous allons nous en assurer en éditant l'année minimum et maximum du dataset :
minYear = data['year'].min()
maxYear = data['year'].max()
print("Timeframe par defaut: {} a {}".format(minYear, maxYear))
Timeframe par defaut: 1960 a 2019
Afin de comparer les pays entre eux nous devons nous assurer qu'ils sont tous couverts par le même timeframe. Voyons tout d'abord si les 207 pays sont bien concernés par la fenêtre 1960/2019 :
mearRange = range(minYear, maxYear+1)
yearSet = frozenset(yearRange)
rangeCheck = data.groupby('country_code')['year'].apply(yearSet.issubset)
nbError = np.where(rangeCheck==False)[0].size
print("Nombre de pays nous couverts par le timeframe {} / {} : {}".
format(minYear, maxYear, nbError))
Nombre de pays non couverts par le timeframe 1960 / 2019 : 62
Malheureusement, 62 pays sur les 207 pays que compte le dataset ne présentent pas systématiquement des observations sur les années 1960 à 2019. Il nous faut, par conséquent, trouver une fenêtre plus courte dans laquelle un maximum de pays sont représentés. Nous allons déterminer ce nouveau timeframe en conservant la borne supérieure à 2019 (année la plus récente) et en faisant glisser la borne inférieure :
fromYear = minYear
nbYears = maxYear-minYear
bestMatched = 0
for i in range(0, nbYears):
yearRange = range(minYear+i, maxYear+1)
yearSet = frozenset(yearRange)
rangeCheck = data.groupby('country_code')['year'].apply(yearSet.issubset)
matchedCountries = np.where(rangeCheck==True)[0]
if matchedCountries.size > bestMatched:
bestMatched = matchedCountries.size
indices = matchedCountries.tolist()
fromYear = minYear+i
print("Meilleur timeframe : {} a {} avec {} pays".format(fromYear, maxYear, bestMatched))
Meilleur timeframe : 1990 a 2019 avec 191 pays
Ce timeframe est beaucoup plus significatif pour notre visualisation. Nous allons par conséquent travailler sur la fenêtre 1990 à 2019. Nous allons isoler cet intervalle et constituer ainsi notre dataset de travail :
data = data[data['country_code'].isin(checkCodeName[indices].index.tolist())]
data = data[data['year'].isin(range(fromYear, maxYear+1))]
print("Le dataset contient desormais {} lignes pour {} pays distincts".
format(data.shape[0], data['country_code'].nunique()))
Le dataset contient désormais 5730 lignes pour 191 pays distincts
Nous avons désormais 191 pays X 30 années, soient 5730 lignes. Nous pouvons continuer.
Enrichissement des données
Le top 5 auquel nous voulons arriver traite des pays d'Asie, or nous ne disposons pas de l'information
concernant la région à laquelle un pays appartient. Nous allons enrichir notre dataset en utilisant
les données mises à disposition par l'institut World Bank Open Data.
Pour information, nous avions déjà traité de l'enrichissement de données depuis cette base dans
cet
article.
Installons puis importons la librairie wbgapi :
!pip install wbgapi --quiet
import wbgapi as wbo
A présent, ajoutons le code région.
dataGeo1 = wbo.economy.DataFrame()
data = pd.merge(data, dataGeo1['region'],
how="left",
left_on=["country_code"],
right_on=["id"])
data.head()
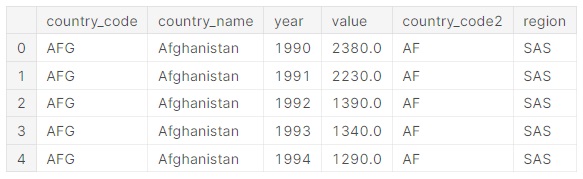
Dans le code ci-dessus, nous avons tout d'abord importé les données économiques issues du package wbo et contenant le
code région qui nous intéresse. Ensuite nous procédons à une jointure entre nos données et les données importées. La clé
étant le code pays de notre côté et l'identifiant (id) du côté des données importées.
Maintenant que nous avons le code région, faisons de même pour le nom de la région :
dataGeo2 = wbo.region.Series().to_frame()
data = pd.merge(data, dataGeo2['RegionName'],
how="left",
left_on=["region"],
right_on=dataGeo2.index)
data.head()
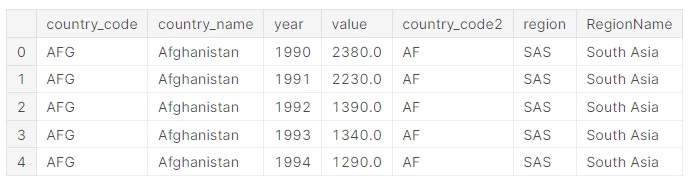
Le principe est exactement le même à l’exception de la source des informations et de la clé de jointure.
Visuel enrichi
Nous y sommes. Les données sont prêtes, il ne nous reste plus qu'à construire le visuel.
Nous allons tout d'abord créer une fonction générique cardHisto qui va prendre en entrée les modalités
de la variable catégorielle à analyser, les valeurs associées à chacune de ces modalités, la palette
de couleur, le titre de notre carte, le coefficient alpha de transparence et enfin le pattern (modèle)
de l'annotation à éditer en face de chaque barre.
Afin que le diagramme soit plus lisible nous allons opter pour un histogramme horizontal sans axe
en abscisses :
import matplotlib.pyplot as plt
def cardHisto(ax, classes, values, colors, title="", alpha=0.7, textPattern=None):
ax.barh(classes, values, color=colors, alpha=alpha)
ax.set_title(title)
ax.invert_yaxis()
ax.get_xaxis().set_visible(False)
for i, v in enumerate(values):
ax.text(ax.get_xlim()[1]/2, i, (v if textPattern is None else textPattern(v)),
color='black', fontweight='bold')
Classement des régions émettrices de CO2 en 2019
La fonction est prête à l'emploi. Commençons par dresser un premier visuel, le classement des régions
émettrices de CO2 en 2019.
Constituons les données dans un dataframe sum_df : Pour ce faire, il nous faut extraire l'année
2019 de notre dataset, puis grouper les émissions CO2 par région pour finalement les trier de façon descendante :
sum_df = data[data["year"] == maxYear].groupby(["RegionName"])["value"].sum().sort_values(ascending=False)
Pour la palette de couleur, nous optons pour un choix aléatoire :
sum_colors = [ '#' + str(hex(random.randint(0,16777215)))[2:] for k in sum_df.index]
Définissons à présent le titre du diagramme et le pattern des annotations. Nous voulons que le texte édité en face de chaque barre soit de type : 99,999 kt
title = 'CO2 emission (kt) by region in 2019'
barTextPattern = lambda v : "{:,} kt".format(round(v))
Les paramètres du visuel sont initialisés, appelons à présent notre fonction :
fig, ax = plt.subplots(1, 1, figsize=(15, 5))
cardHisto(ax, sum_df.index, sum_df.values, sum_colors,
title=title, textPattern=barTextPattern)

Evolution des émissions CO2 en Asie entre 1990 et 2019
A présent, éditons deux diagrammes juxtaposés : les top 5 des pays émetteurs de CO2 en Asie en 1990 et 2019. Comme pour le diagramme précèdent, préparons nos données puis appelons la fonction :
#Nous definissons la region a analyser
region ="EAS"
#Extraction du top 5 des pays emetteurs sur la region en 1990
df = data[data["year"].isin([fromYear, maxYear])].groupby(["region", "year"])["value"].nlargest(5)
top_df1 = df[(df.index.get_level_values('region') == region) & (df.index.get_level_values('year') == fromYear)]
top_df1 = data.loc[[elt[2] for elt in top_df1.keys()],]
#Extraction du top 5 des pays emetteurs sur la region en 2019
top_df2 = df[(df.index.get_level_values('region') == region) & (df.index.get_level_values('year') == maxYear)]
top_df2 = data.loc[[elt[2] for elt in top_df2.keys()],]
#Definition du titre general et du pattern des annotations
fig.suptitle(top_df1.iloc[0]['RegionName'] + ' : CO2 emission evolution from 1990 to 2019')
barTextPattern = lambda v : "{:,} kt".format(round(v))
#Definition du canvas
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))
#Edition du premier diagramme (top 5 en 1990)
title = 'Year ' + str(fromYear)
cardHisto(ax1, top_df1['country_name'], top_df1['value'], top_df1['color'],
title=title, textPattern=barTextPattern)
#Edition du premier diagramme (top 5 en 2019)
title = 'Year ' + str(maxYear)
cardHisto(ax2, top_df2['country_name'], top_df2['value'], top_df2['color'],
title=title, textPattern=barTextPattern)
Crédits
Miniature issue de Image de vecstock sur Freepik
Retrouvez dans la rubrique "Nos datasets" toutes les données dont vous aurez besoin pour tester et pratiquer !